Understanding KNN with Malware File Prediction
The K-Nearest Neighbors (KNN) Algorithm is a powerful and intuitive machine learning method used for classification and regression tasks. This blog post explains KNN in detail, demonstrates its application to a dataset for predicting file legitimacy, and interprets the results step by step.
What is K-Nearest Neighbors (KNN)?
KNN is a supervised machine learning algorithm used to classify data based on the characteristics of its nearest neighbors. Key aspects of KNN include:
- No Assumptions: KNN does not make assumptions about the data’s underlying distribution.
- Instance-Based Learning: It memorizes the training dataset to classify new instances.
- Distance-Based: Predictions are made based on the distance between the test point and its nearest training data points.
- Key Parameters:
- k: The number of neighbors to consider.
- Distance Metric: Determines how “closeness” is calculated (e.g., Euclidean, Manhattan).
About the Dataset
The dataset consists of features extracted from files to predict their legitimacy:
- Features: Include technical attributes like
SizeOfOptionalHeader,MajorLinkerVersion,SizeOfCode, and resource entropy. - Target Variable:
legitimate(1 = Legitimate, 0 = Malicious). - Preprocessing: Dropping irrelevant columns (
Name,md5) and standardizing features to ensure equal weighting in distance calculations.
Kaggle Link: https://www.kaggle.com/datasets/divg07/malware-analysis-dataset
Implementation
Below is the Python implementation segmented into logical parts with explanations.
Load and Preprocess the Dataset
import numpy as np
import pandas as pd
# Load dataset
dataset = pd.read_csv('data.csv', sep='|')
# Separate features and target variable
X = dataset.drop(['Name', 'md5', 'legitimate'], axis=1).values
y = dataset['legitimate'].values
from sklearn.model_selection import train_test_split
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=2)
The columns Name and md5 are identifiers and do not influence the classification. These are dropped to focus on technical attributes. Features (X) and target (y) are separated for modeling.
Standardize the Features
from sklearn.preprocessing import StandardScaler
# Feature scaling
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
- Standardization ensures that features have a mean of 0 and a standard deviation of 1, preventing large-scale features from dominating the distance calculation.
Determine the Optimal Number of Neighbors (k)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
k_values = range(1, 11)
accuracies = []
for k in k_values:
classifier = KNeighborsClassifier(n_neighbors=k, metric='minkowski', p=2, weights='distance')
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
# Plot accuracy vs. k
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(k_values, accuracies, marker='o')
plt.title('Accuracy vs. Number of Neighbors (k)')
plt.xlabel('Number of Neighbors (k)')
plt.ylabel('Accuracy')
plt.xticks(k_values)
plt.grid(True)
plt.show()
best_k = k_values[accuracies.index(max(accuracies))]
print(f"The best number of neighbors (k) is: {best_k} with an accuracy of {max(accuracies):.4f}")
Output
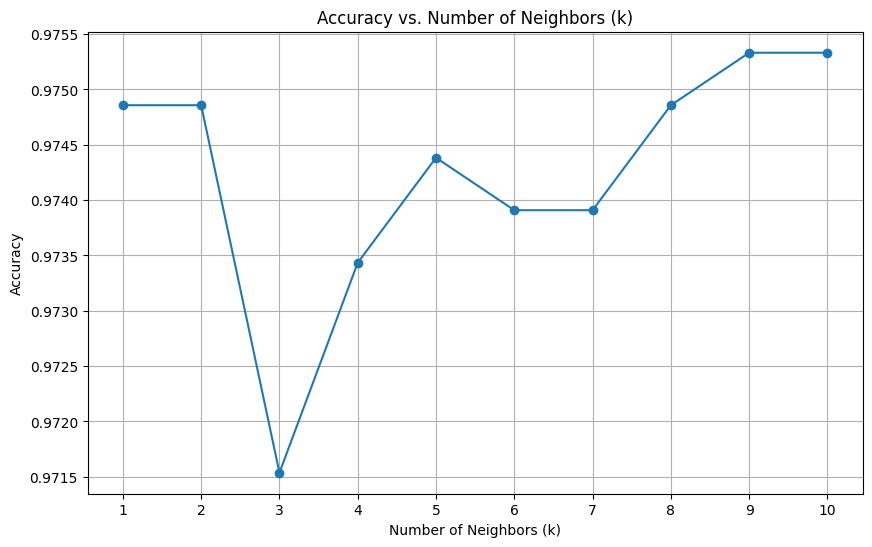
The best number of neighbors (k) is: 9 with an accuracy of 0.97531
It is essential for identifying the optimal number of neighbors (k) in the K-Nearest Neighbors (KNN) algorithm, which directly impacts model accuracy. The parameter k determines how many nearby data points are considered when making predictions, influencing the balance between overfitting and underfitting. By iterating through a range of k values (1 to 10), the code evaluates model performance using accuracy as the metric.
Each k value is tested with the given training and test data, and the results are visualized in a plot to reveal how accuracy changes with different k. This allows data scientists to make an informed decision about the best k, ensuring optimal performance.
Additionally, the configuration of the KNN classifier in this code uses the Minkowski metric (p=2, equivalent to Euclidean distance) and weighted distances, giving more importance to closer neighbors. This approach ensures that proximity plays a critical role in prediction, which is particularly useful when data points vary in density.
Build the Final Model
# Final model with the best k
classifier = KNeighborsClassifier(n_neighbors=best_k, metric='minkowski', p=2, weights='distance')
classifier.fit(X_train, y_train)
# Predict on test set
y_pred = classifier.predict(X_test)
We will be using the best_k that we found from the previous output visual and apply it in the KNeighborsClassifier function from the library Sklearn. For building a model, we will use the train set that we split from the dataset. For testing a model, we use the test set. There is another form of set known as the validation set which is used in Neural network to validate each epoch of a neural model training. To learn more about neural network, visit the tag neural-network in the blog/ page.
Evaluate the Model
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# Evaluate performance
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"Final Model Accuracy: {accuracy}")
print("Confusion Matrix:")
print(conf_matrix)
print("Classification Report:")
print(class_report)
Output
Final Model Accuracy: 0.9753320683111955
Confusion Matrix:
[[1360 22]
[ 30 696]]
Classification Report:
precision recall f1-score support
0 0.98 0.98 0.98 1382
1 0.97 0.96 0.96 726
accuracy 0.98 2108
macro avg 0.97 0.97 0.97 2108
weighted avg 0.98 0.98 0.98 2108
The Confusion Matrix gives a detailed breakdown of the our model’s predictions and helps us understand its performance. It is a function from the module metrics in Sklearn library.
In this case, the model correctly identified 696 legitimate files (True Positives) and 1360 malicious files (True Negatives).
However, there were 22 instances where legitimate files were incorrectly classified as malicious (False Positives), and 30 instances where malicious files were misclassified as legitimate (False Negatives). This demonstrates that while the model performs well overall, there are some instances of misclassification that could be critical depending on the application.
The Classification Report highlights the model’s ability to distinguish between legitimate and malicious files effectively. It provides us with precision,recall for each class of prediction.
For legitimate files, the precision is 0.98, meaning that 98% of the files predicted as legitimate are indeed legitimate. Similarly, the recall is also 0.98, indicating that the model successfully identifies 98% of all actual legitimate files.
These high precision and recall scores reflect the model’s reliability and robustness, ensuring that it minimizes the risk of misclassifications while maintaining a strong overall performance.
Perform Cross-Validation
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(classifier, X, y, cv=10, scoring='accuracy')
print(f"Cross-Validation Scores: {cv_scores}")
print(f"Mean Accuracy: {cv_scores.mean():.4f}")
print(f"Standard Deviation: {cv_scores.std():.4f}")
Cross validation is the process by which we change the split of the dataset into n numbers and divide them into train and test to check the consistency of our model across the dataset. Finally, In this dataset, CV was performed to ensure the model’s stability and generalizability. The mean cross-validation accuracy was 0.9694, with a low standard deviation of 0.0055, demonstrating that the model’s performance is consistent across different subsets of the data.
KNN proved to be a highly effective classifier for predicting file legitimacy in this dataset. Its simplicity and adaptability make it a valuable tool for binary classification problems, provided the data is preprocessed and the right k is chosen.
Enjoy Reading This Article?
Here are some more articles you might like to read next: